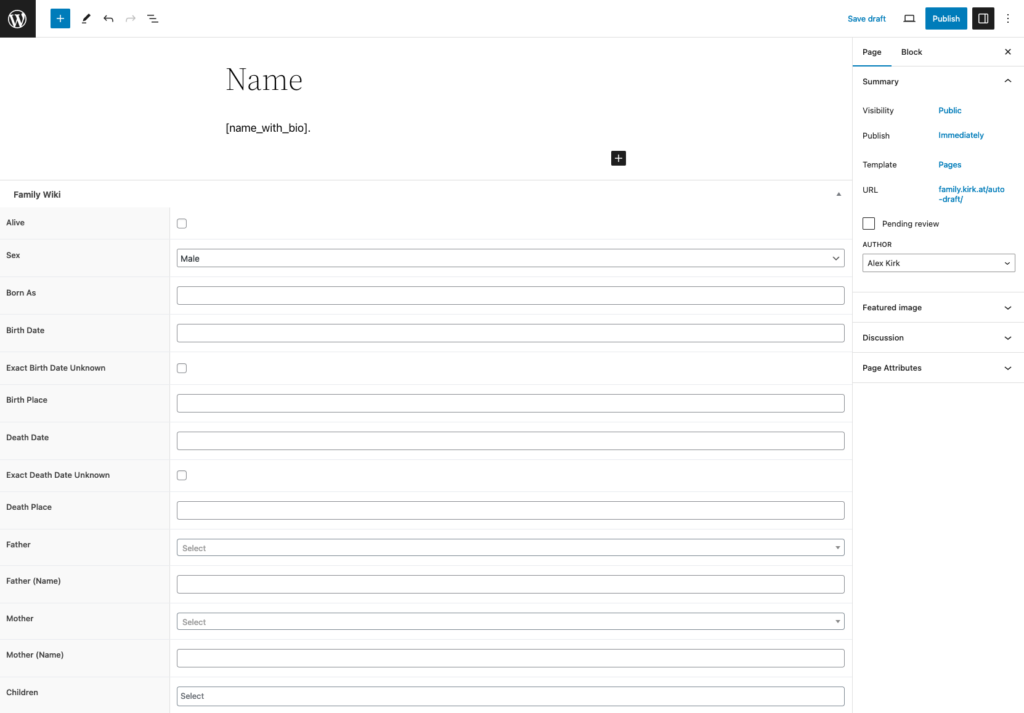
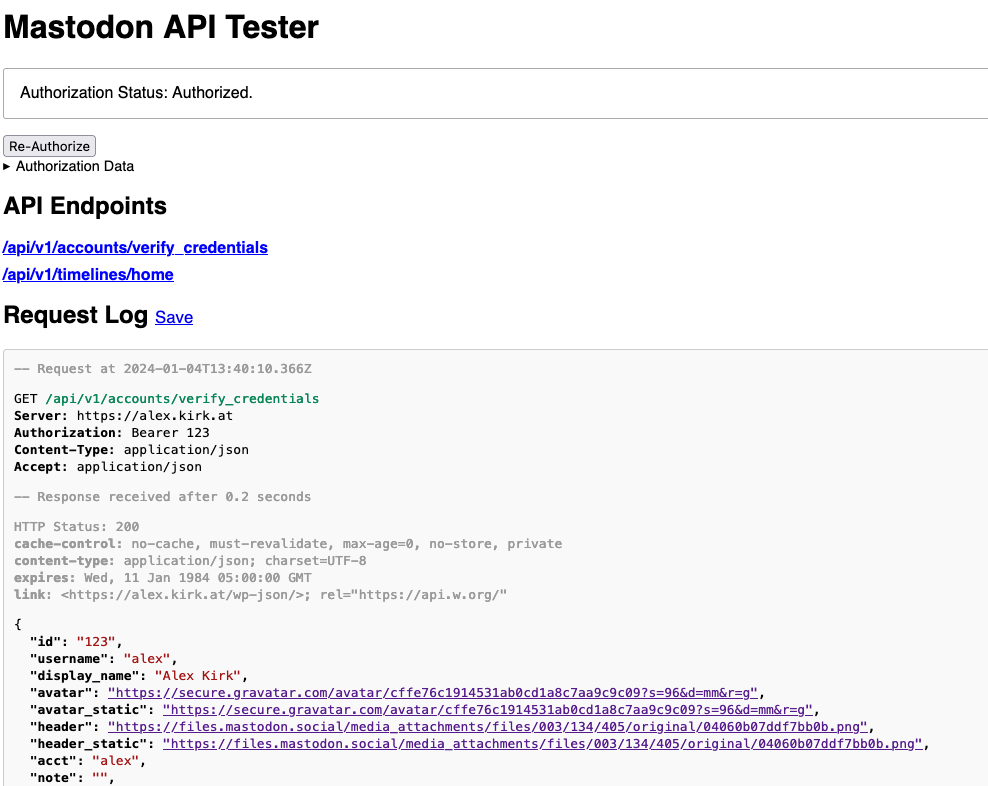
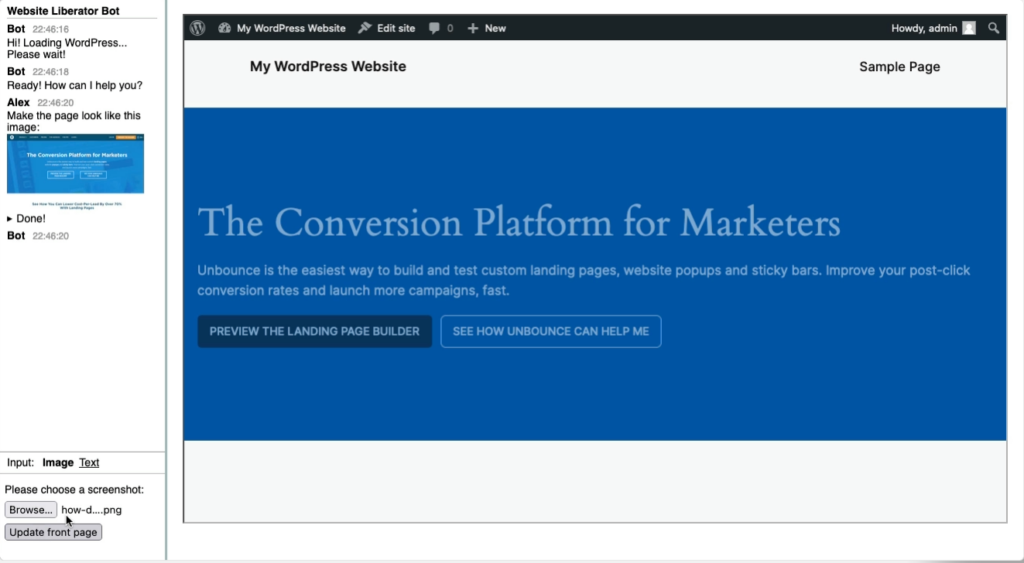
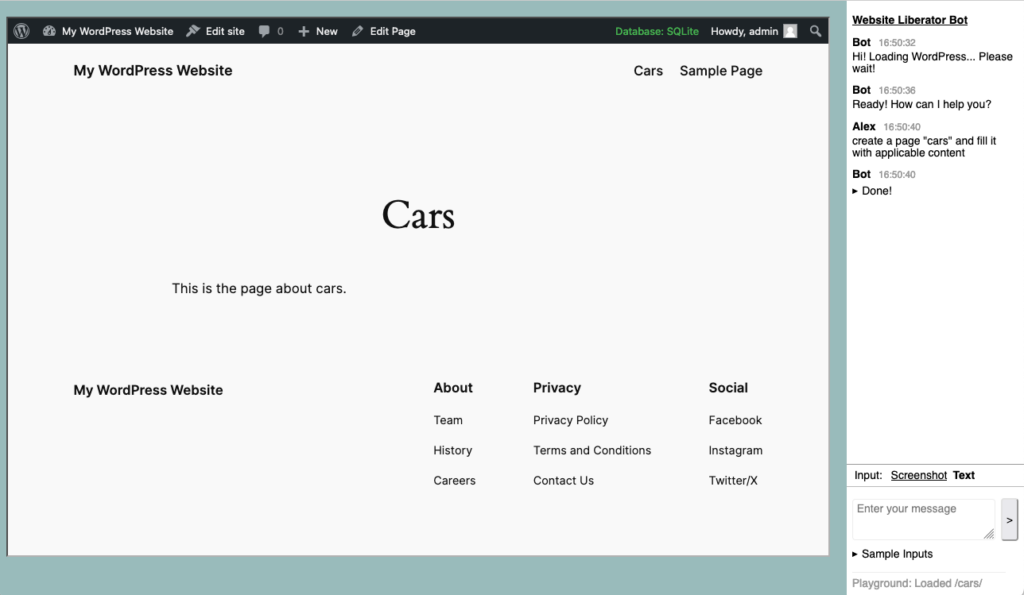
Jeremy Keith posted about bookmarklets that he uses for testing websites where he specifically likes those that just pass on the current URL to a service. Those bookmarklets typically have a structure like:
javascript:location.href='https://example.com?s='+escape(location.href)I use those for my Friends WordPress plugin, too. That’s the one where you can follow people via RSS or ActivityPub and see the feed in a private section of your blog or even in Mastodon apps.
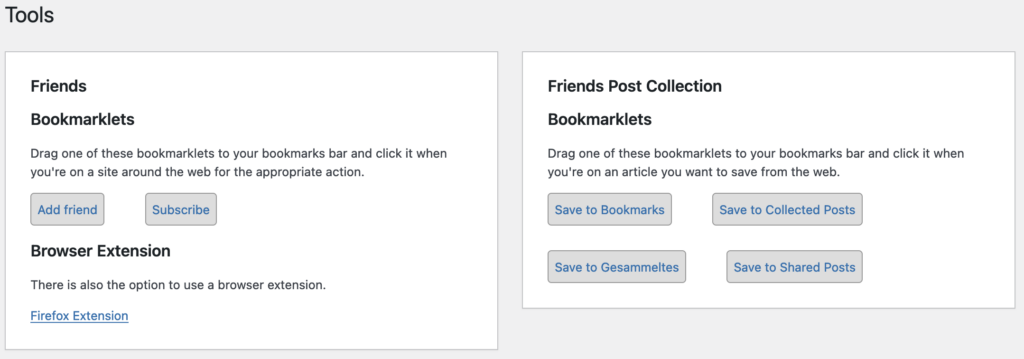
So, to follow the current website, you’d click on a bookmarklet like this:
javascript:location.href='https://example.com?add-friend='+escape(location.href)I have another WordPress plugin called Post Collection, where you can save articles to your blog. Both to be able to search them later, or, with my Send to E-Reader plugin, to send them to your favorite reading device as a compiled e-book with chapters. Although the bookmarklet that you’d typically install has some logic to post the whole current page body so that it also works on non-public posts, there is also a version that looks like this:
javascript:location.href='https://example.com?user=123&collect-post='+escape(location.href)One particularly nice thing about these style of bookmarklets, is that while unfortunately they don’t (or didn’t?) work on Firefox Mobile, you can use an Android app called URL Forwarder to share a URL from any other app which comes in quite handy when you use other apps to discover interesting content (such as awesome the Glider app for Hacker News).

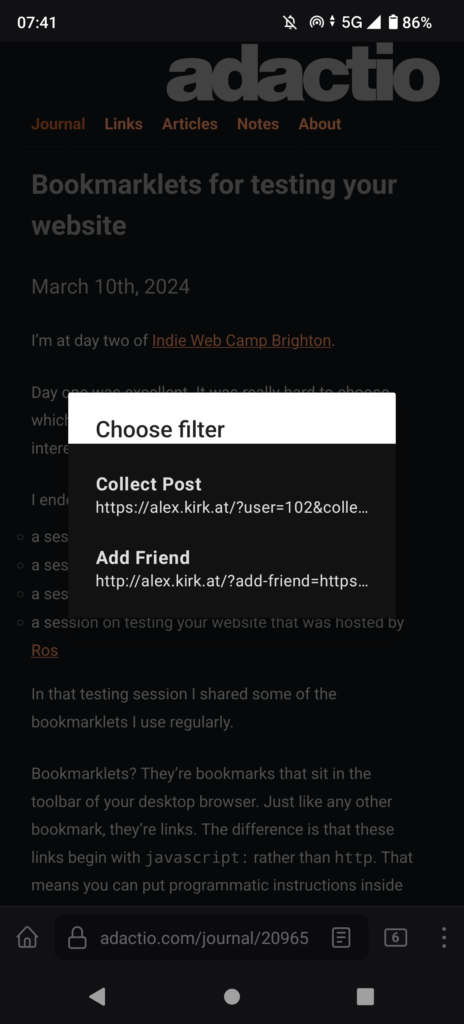
I have only added my two bookmarklets here, but most of the ones Jeremy mentioned could also be added.
By the way, I have some history with bookmarklets. In 2005, I created a bookmarklet manager called Blummy. It’s still alive but dormant (ping me if you want to try it, signups have been spammed to death).
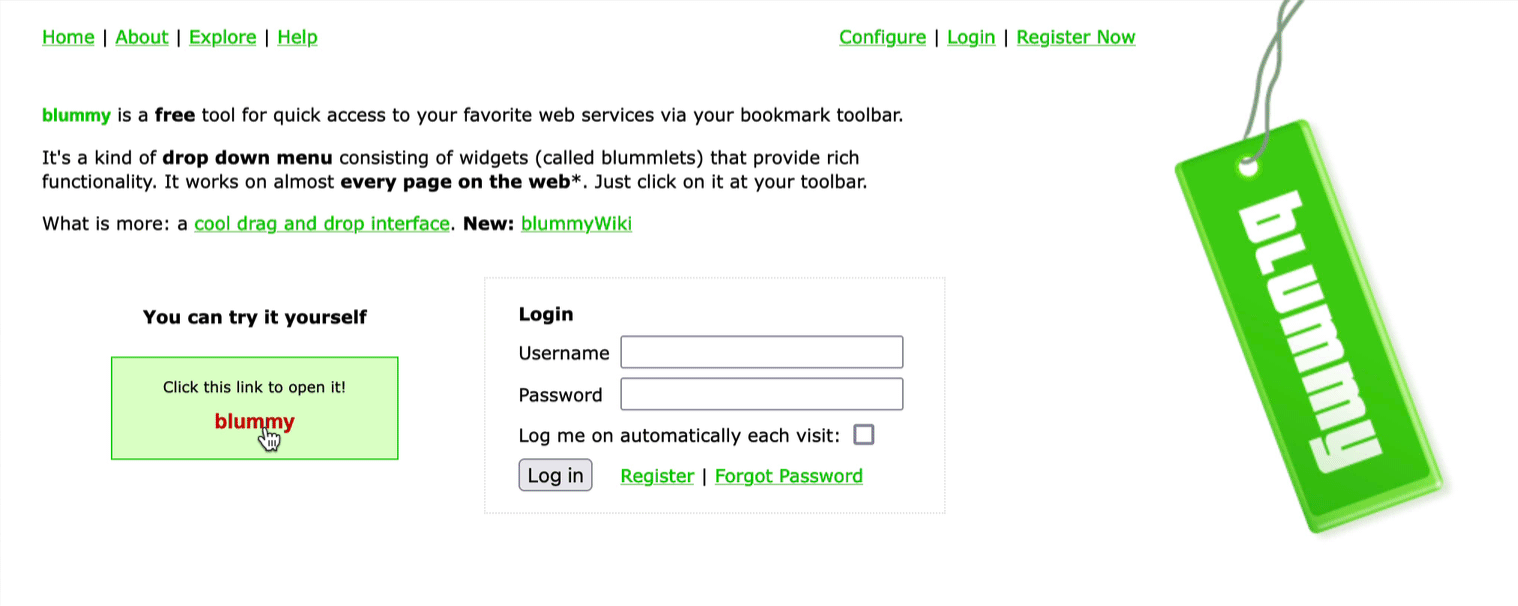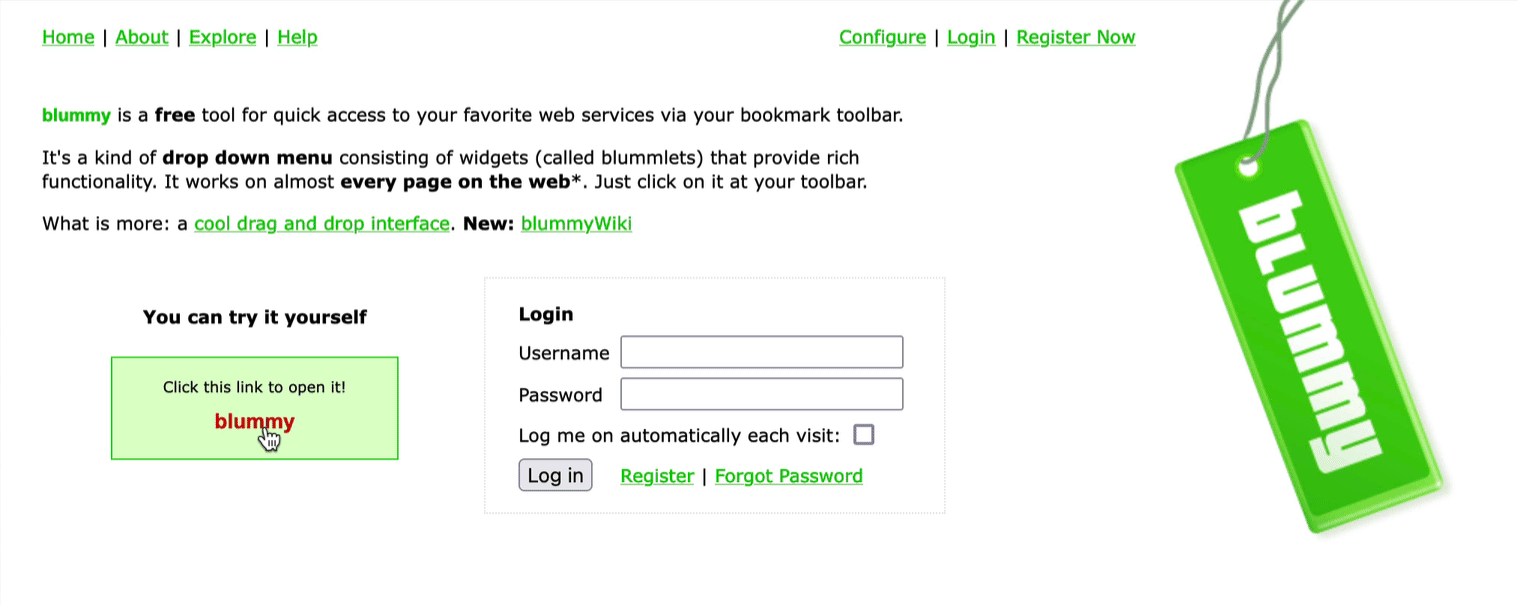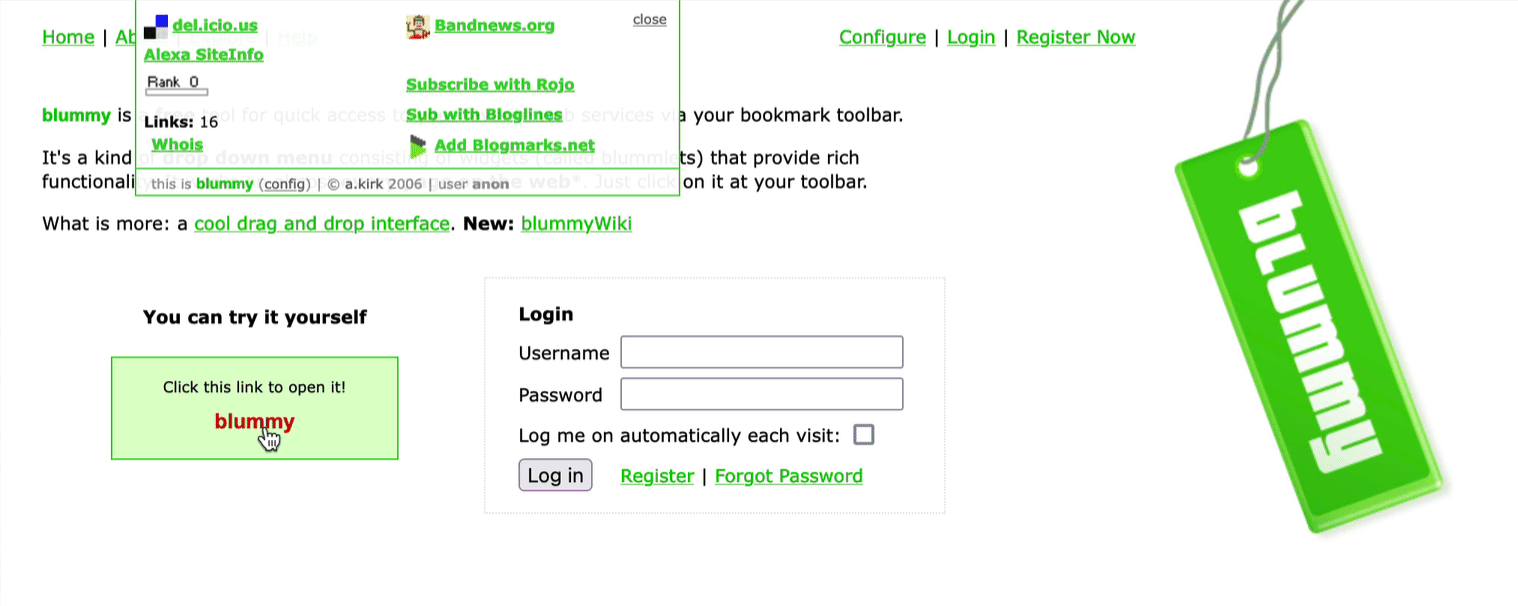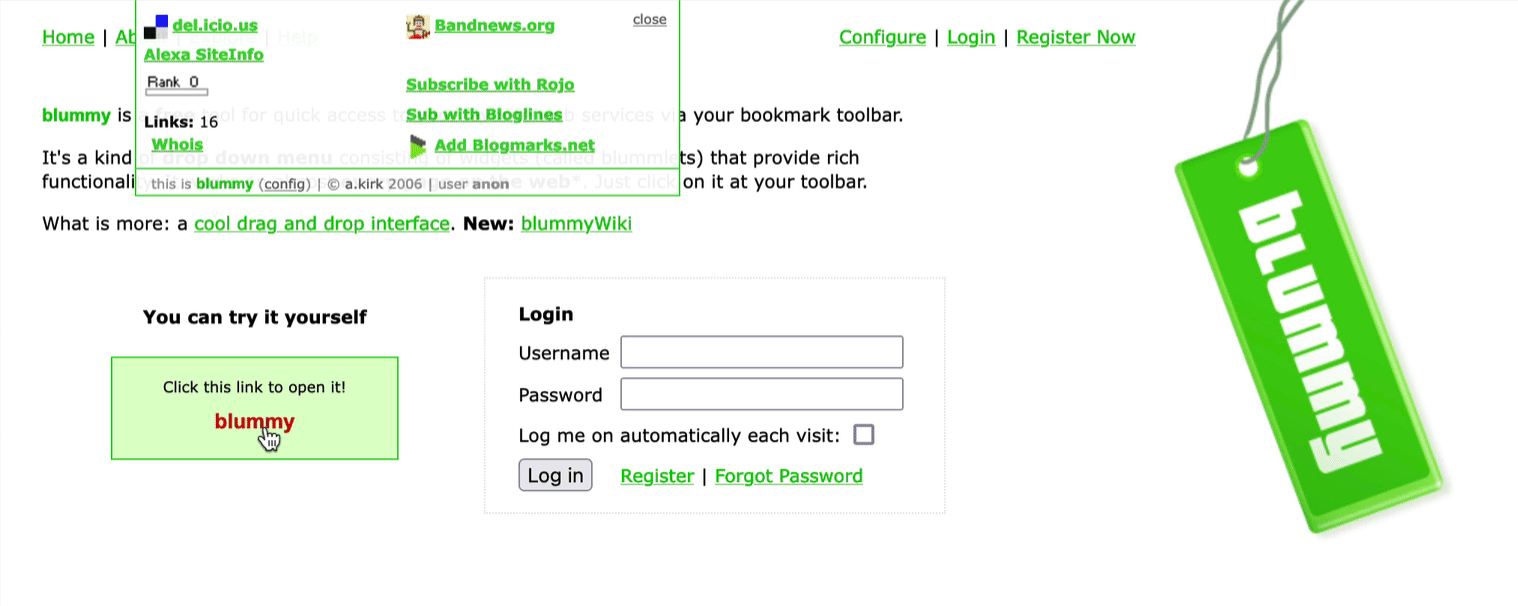
Bookmarklets have come out of fashion but were very important back then. I wished browsers would support them better and make installing them a little less awkward. They are always like a little swiss army knife to me.