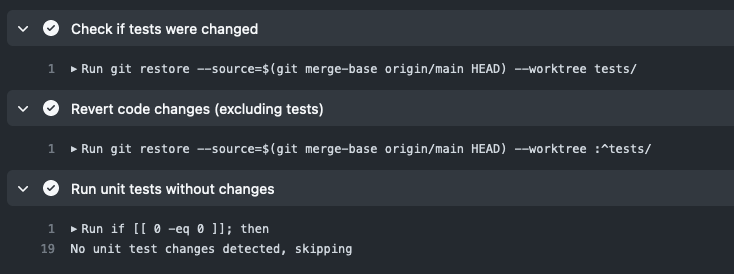
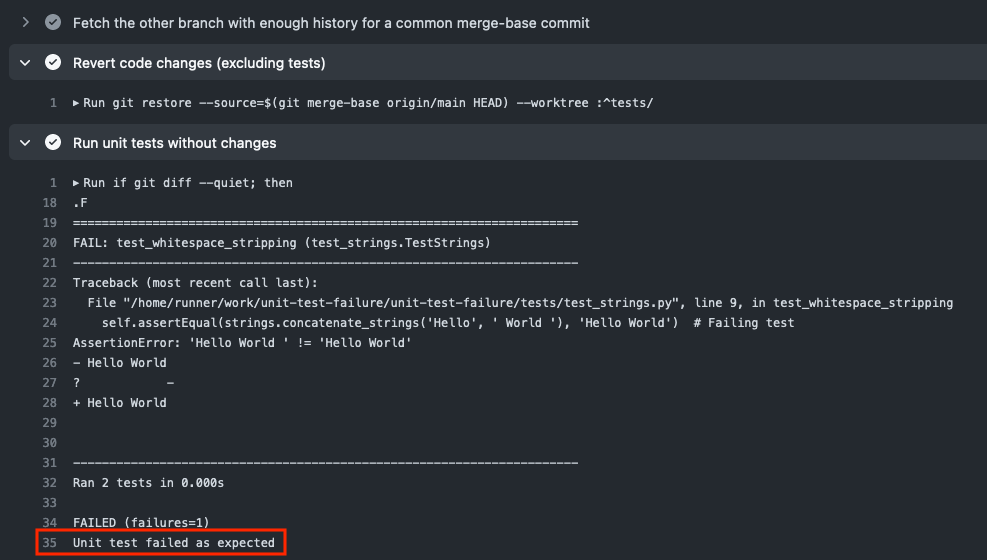
I’ve been working on this experiment, combining OpenAI’s gpt-4-vision-preview with WordPress Playground to create a website based on a screenshot.
This follows on the heels of Matt Mullenweg’s announcement at the 2023 State of the Word that in 2024, the WordPress project wants to work on Data Liberation.
While the typical approach to migrating data is to build importers for specific services, a truely universal migration could happen through screenshots. With AI vision this might now be in reach.
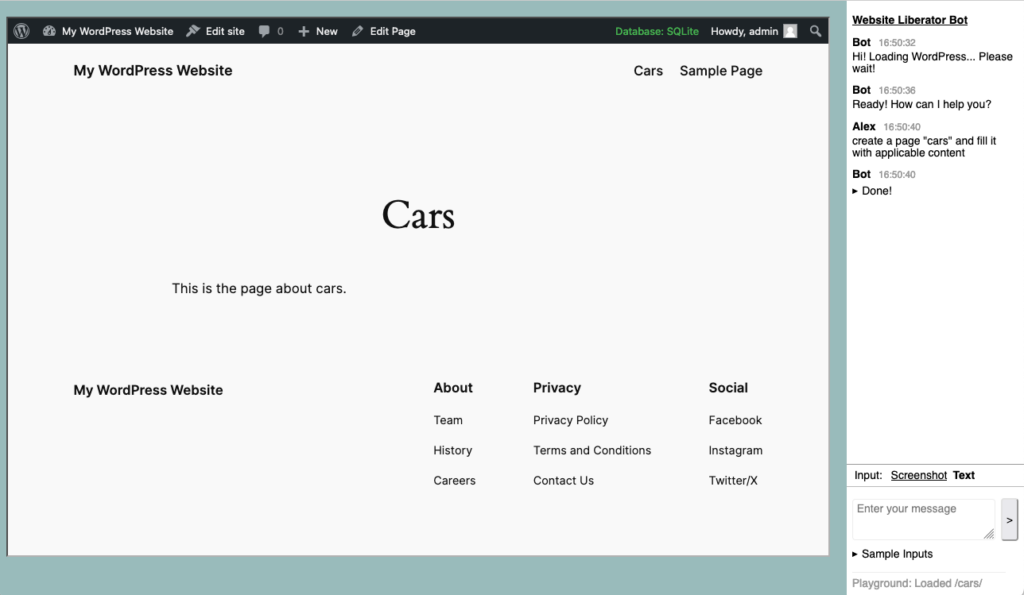
So I built this prototype that combines a OpenAI-powered chat interface with WordPress Playground. First a screenshot, a screen recording further down.
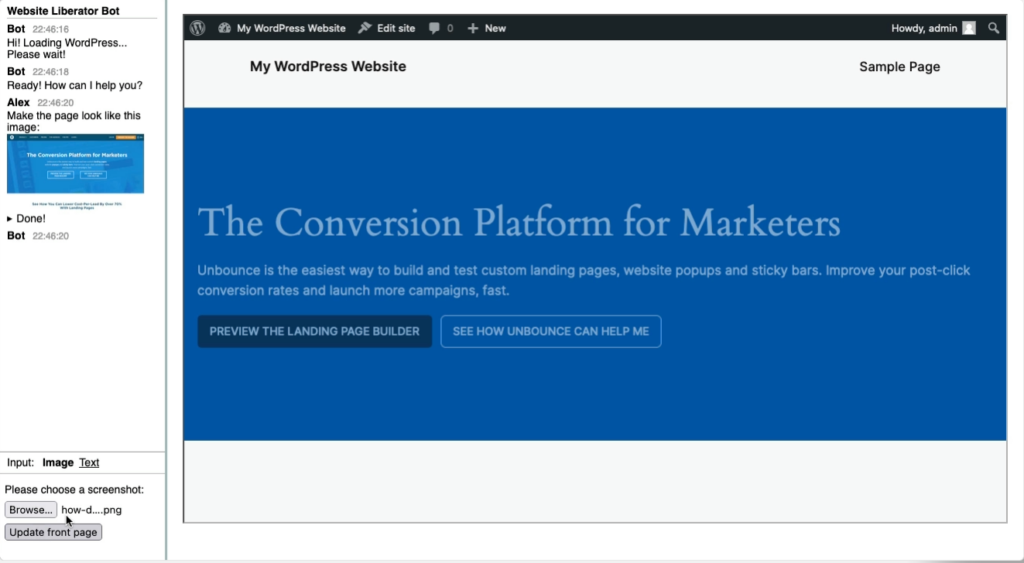
So this is only a start. The website somewhat resembles the screenshot but it’s far from being pixel perfect.
My idea is that you’ll work together with the assistant in refining the site. It can help you update, you can ask it questions. An import is rarely perfect from the start but you can see and test the result right away in the browser and refine it.
I imagine that when done, you can then transfer the site to a web hoster who from then on can host your website for everyone.
You can try this yourself here, you “just” need an OpenAI API key that will be stored in your local storage: https://akirk.github.io/website-liberator/
Source (very unpolished) at https://github.com/akirk/website-liberator/
Some notes on this first implementation:
- Every message is a new conversation. Modifying a website can be token intense, so for now it cannot refer to previous messages.
- It’s using function calling to allow OpenAI to gather more information to fulfil the request.
- Chosing the right functions to provide can be tricky.
- I’ve even gone so far to adapt the list of available functions depending on how deep you are in the function calling stack:
- If it has a function available to navigate the user to a screen, it would prefer to do that vs just creating a page itself. By removing that function early on, it needs to do the latter.
- It uses different models depending on the task. gpt4-vision-preview for the screenshot, gpt-3.5-turbo for the rest. I need to experiment more with gpt-4 for the latter tasks.
Finally, a screen recording of an early iteration, I have since moved the chat to the right side.
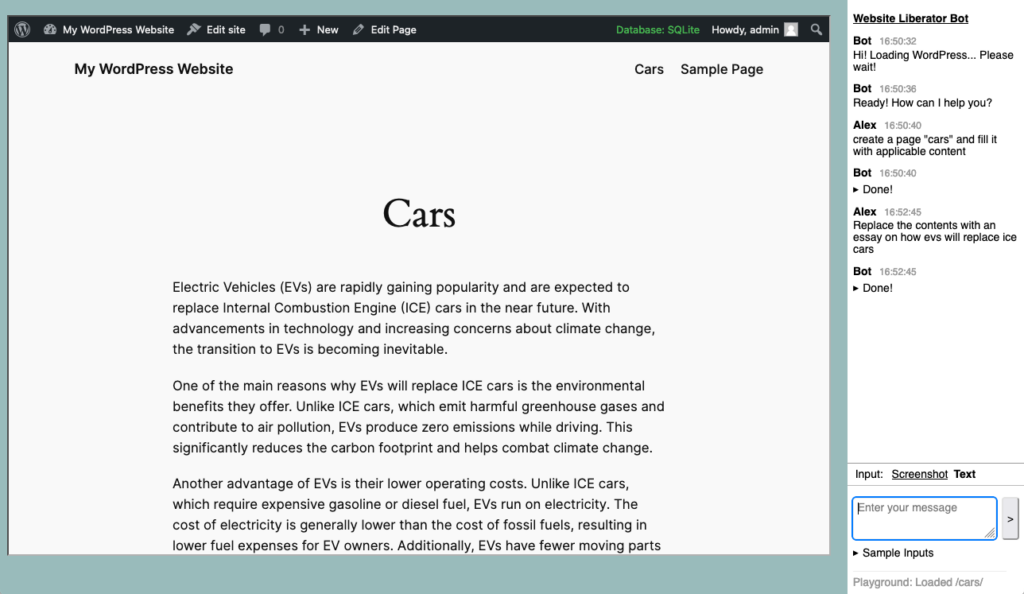
As I’ve been working on the prototype, it has shown to be interesting to have the bot be there just for customizing sites, it can create and modify pages, update settings of the website. Maybe install plugins.
So starting with a basis from screenshots and imported data, it might just be able to assist you to arrive at a comparable WordPress website, and all with the ease and effortless setup of WordPress Playground. I wonder where we can take this!
Bonus
Some screenshots from a recent version: