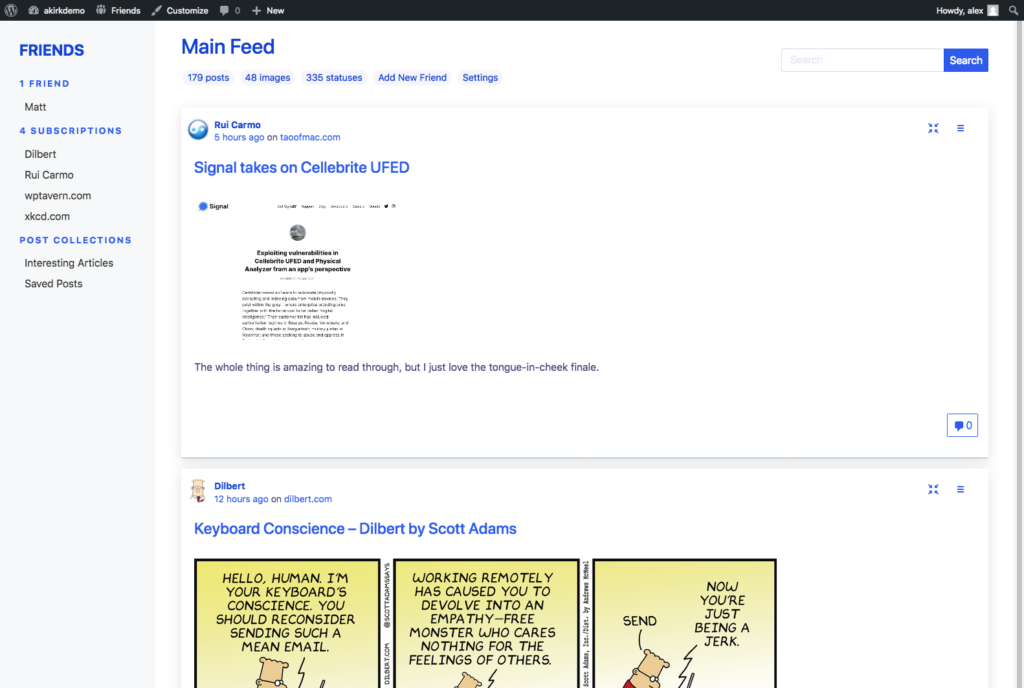
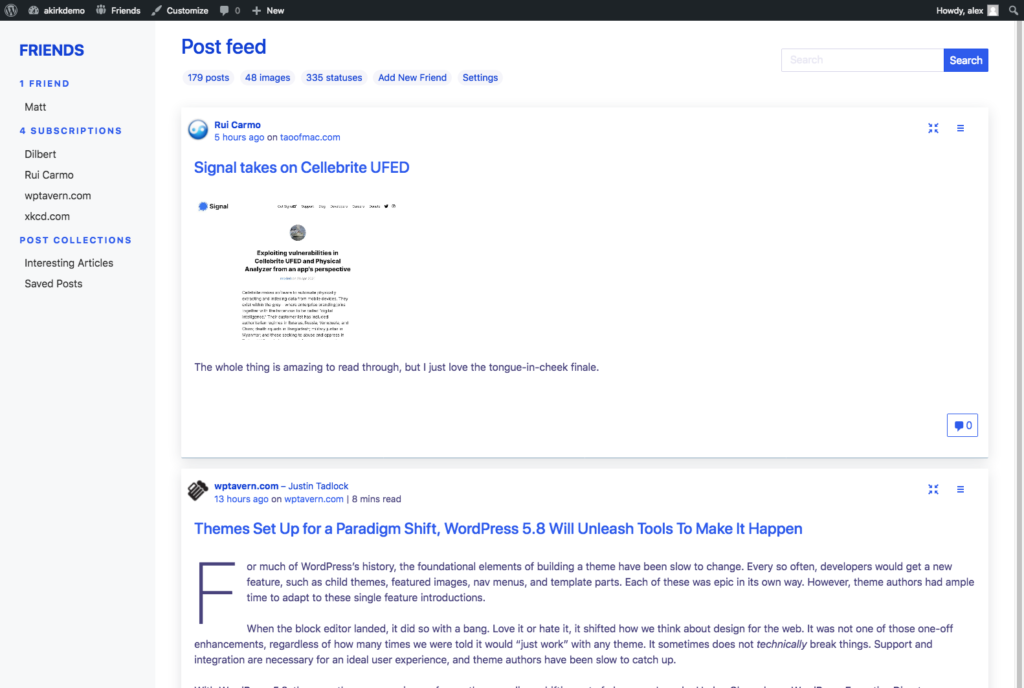
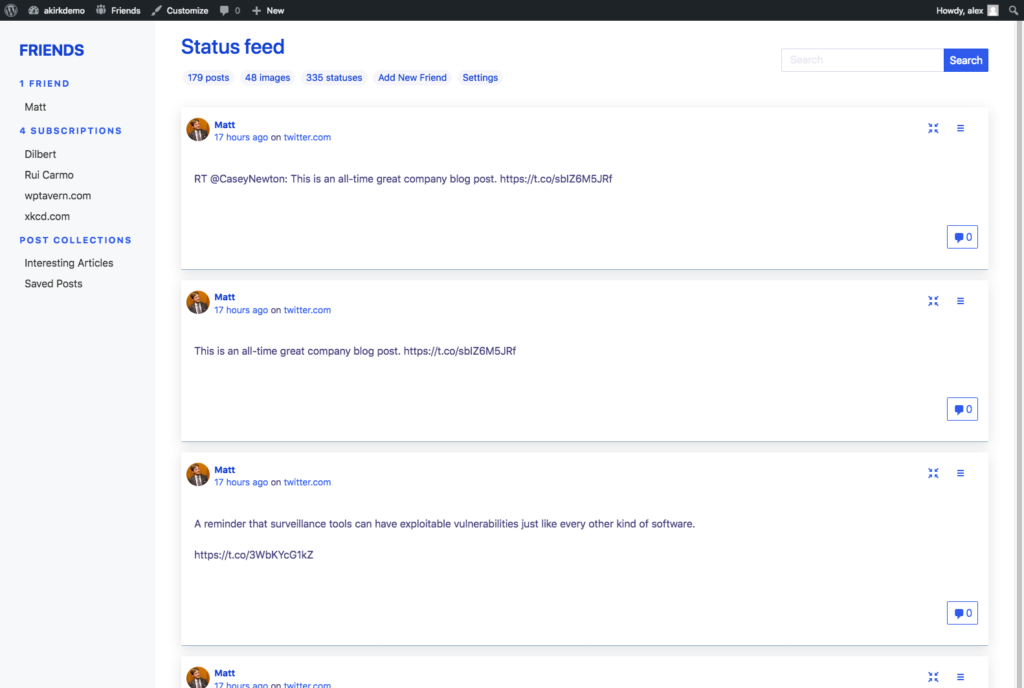
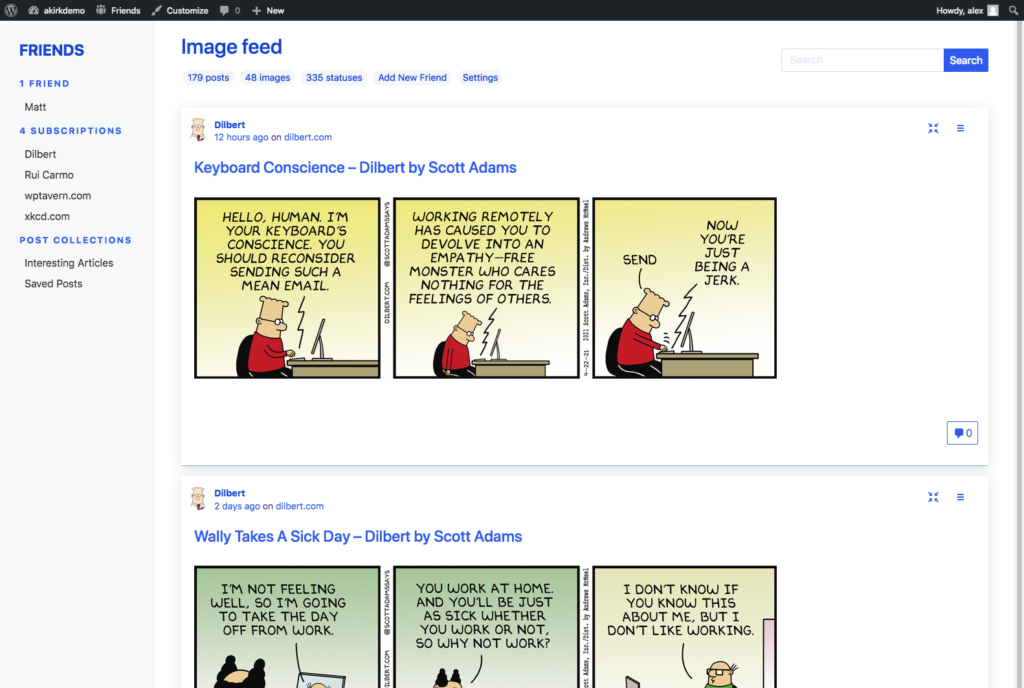
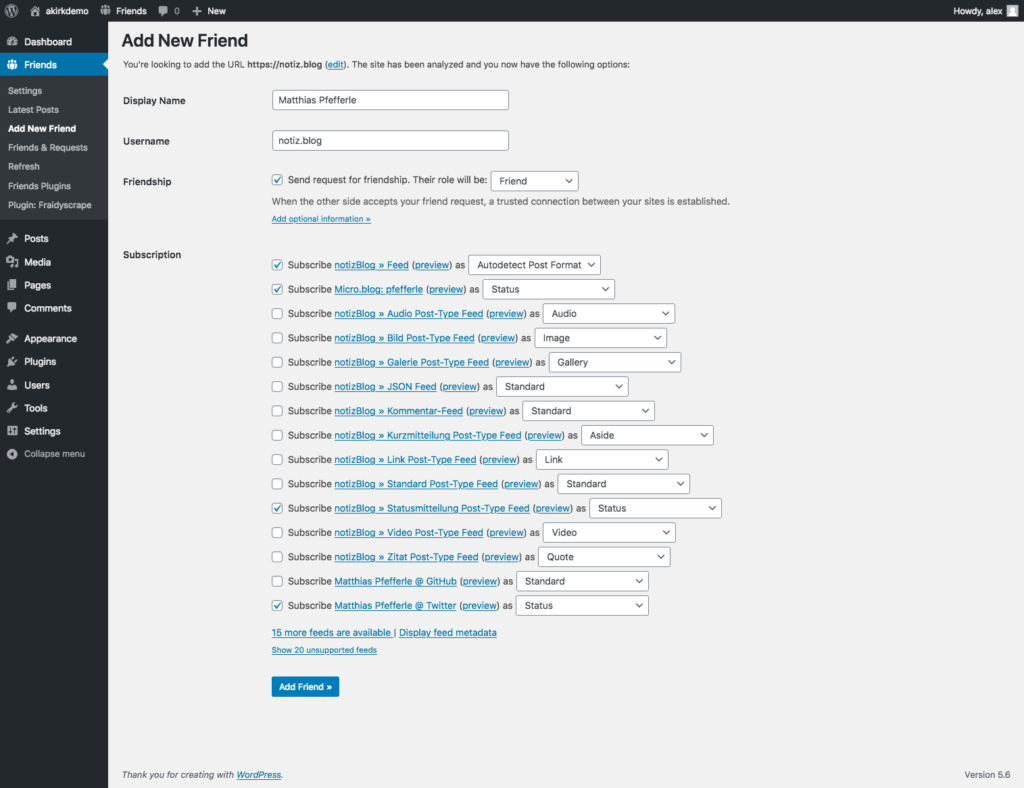
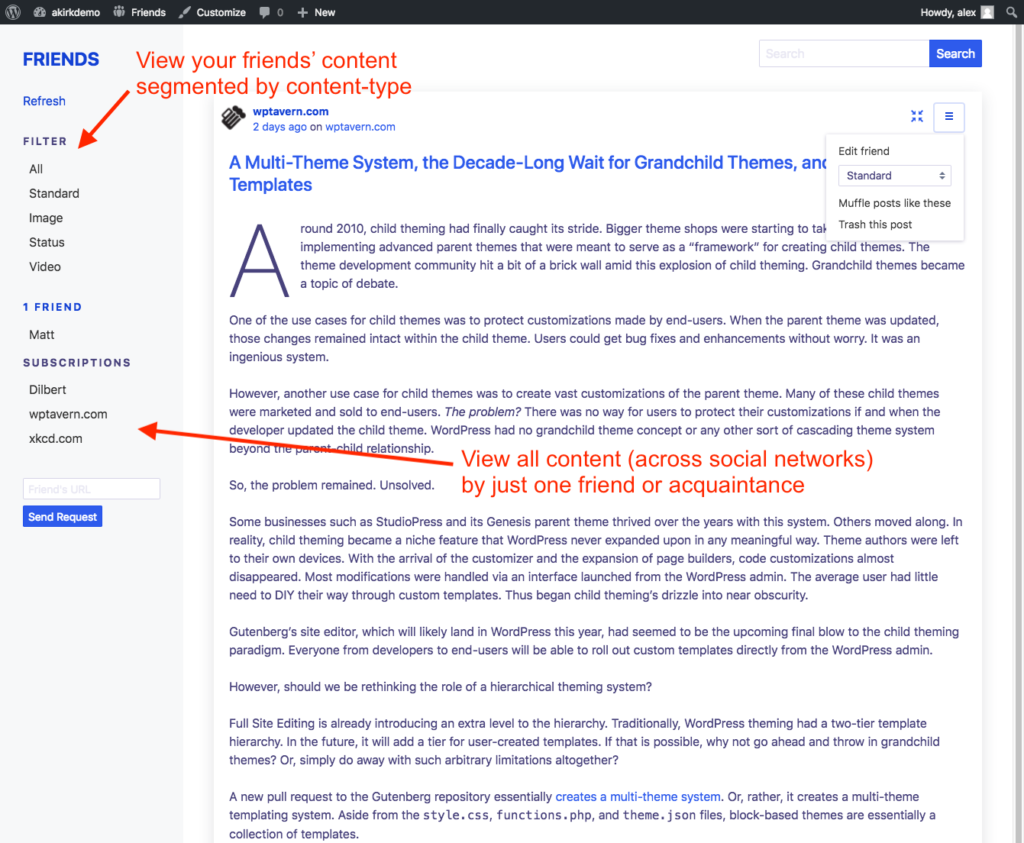
A big motivation for building the Friends Plugin is to be able to follow what my friends and family are up to. Probably the most important “follow technology” is good old RSS.
While mostly used for public posts, there are many examples of how it can deliver posts not meant for the public: the solution are individual RSS feeds per subscriber, for example paid podcasts, or like the Friends plugin gives specific feeds to friends that can contain private posts.
Now reality is that (no longer) every platform has RSS feeds. It’d be easier if they just provided themt but alas. There are plugins for the Friends plugin itself that make use of projects that have built custom parsers for specific services: Fraidyscrape and RSS Bridge.
Now unfortunately, a lot of friends and family post to Facebook or Instagram. It’s just impossible to follow these friends outside of the platforms.
They don’t provide (authenticated) RSS feeds. That would solve all of this.
They rate limit and quickly block IPs (especially Instagram) that try to read a few posts unauthenticated.
It’s unintuitive, developer centric and needs approval to get an API key, so it’s not something every user of the plugin can be asked.
Their HTML is scrambled with random class names, preventing any classic scraping.
So in the end, the content of my friends and family is locked in. It would be a solution for them to create their own blog (IndieWeb style) and share their content that way. But I am realistic enough to understand that the hurdles are great. They are already connected to their friends inside Facebook or Instagram. They get lots of likes and responses there. They are used to the UI and the apps. It’s just not good for anyone who doesn’t want to join the Facebook ecosystem and be exposed to their ads.
… we just don’t realize it. If you think about it, most of the social network services are specialized RSS Readers that combine consuming with creating. (Just to be clear, these social networks don’t provide RSS feeds, what I’m saying is that what they do could be done with RSS feeds.)
Take Facebook, for example:
If you follow someone, you’re subscribing to their RSS feed.
If you like a page, you’re subscribing to their RSS feed.
If you become friends someone, you’re subscribing to their RSS feed and vice versa.
If you view your timeline, you’re looking at all posts by your subscriptions (usually modified/filtered by Facebook).
If you post something, it’s added to your RSS feed and the people who are subscribed to you (via follow or friendship) get your post in their feed.
Twitter is similar, they just limit the post format to “status”. Instagram limits the post format to “image”. Tiktok to “video”.
Easily reachable and searchable user base (= audience).
Easy account creation (just sign up here).
They combine consuming with creation.
I see a possible solution in WordPress. There are many options to get WordPress hosting with your own domain. With the Friends Plugin you can then combine consuming and creating. The Friends plugin allows you to consume the web your way, WordPress is a well established way of creating content.
By using post formats, you can also create different types of content and consume the same kind of incoming content combined. See the screenshots above, showing the main, combined feed, an image feed and a status feed.
Also, commenting on posts is built in to WordPress. With a friendship based approach you can even open up comments just to friends, which can reduce the usual “spam problem.”
What’s still missing for is the convenience of single-purpose apps. The cool thing is that these apps would talk to your own server which handles retrieving of followed content vs. this being relayed to a third party (who then knows the follow patterns of everyone on their platform). With Sunlit, micro.blog has implemented something like this for photo sharing inside their micro.blog platform but I believe this could be done for “RSS” as well.
The Indieweb movement follows very similar ideas to what I described above. The concept of webmentions allows you to respond to a post by posting to your own server, sending a ping to the original article. While the WordPress + Friends approach might be a bit more integrated, I see webmentions as a reasonable bridge between the worlds.
All in all, I believe having a personal blog is good for the health of internet. It’s unfortunate that in their history, personal blogs have this huge focus on “being public.” I believe it is equally well suited to be a place for more private communication, and especially a place where you can consume the web the way you like.
The one thing I didn’t want to do, though, is to connect my site to WordPress.com. For the most part because I didn’t intend to use any of the functionality that requires the WordPress.com connection.
The difficulty in this: normally, you can’t actually use Jetpack until you connect the site to your WordPress.com account. This behavior is in place so you can enjoy a friction-less experience after the connection is established (i.e. you can activate any of its features whether or not it needs the connection).
In my case, the connection is not needed for using the Slideshow block since it works with the local media library.
So, I present not a hack but an official way to use Jetpack without a WordPress.com connection: it’s called Offline Mode.
You activate it by adding a constant or filter to your wp-config.php, for example:
define( 'JETPACK_DEV_DEBUG', true );
While it is intended for local installs and actually development, it is useful if you just want to use a single feature of Jetpack that doesn’t require the connection.
Many people say that Jetpack is slow because it’s so big. It is indeed huge from a file size and feature perspective, but also it’s very optimized, so that it will only load the PHP or JS code it needs. The other files lay dormant in your file system and don’t contribute to the loading or rendering time of your site.
There is something that I feel is not right with today’s web structure. We, as the population of the web, create so much content that ends up on servers of large companies. We could own our data.
Therefore, I’d like to help reduce everyone’s dependency on third party platforms for their online activity.
Vision
You use your own server for publishing and interact with other people’s content on their server.
Since everybody follows this method, your content only reaches the people it is meant for, without involving a third party in the distribution.
You interact using the same means of today: web UI, mobile apps; the difference is that they don’t talk to a third-party server, neither for publishing nor getting and interacting with others’ content.
Note: in the following text I use the word “server” somewhat synonymous for the WordPress+Friends setup but it there could be alternative implementations. Also, server doesn’t mean “a dedicated machine somewhere,” you just need web space where you can install WordPress, which doesn’t mean it has to be expensive. For example, wpfriends.at is hosted for €1,90/month incl. domain.
Separation of Content
Today, separate social networks exist for different types of content; for example short content has its home on Twitter, Instagram is for photos. Facebook is a mix of this but allows for private content. Instant messengers like WhatsApp (or Facebook groups) are very clear about who the content or conversation is for.
So, separating content makes for a more homogeneous experience when consuming the content, also you have a good grasp of where (and for whom) you want to publish your content.
On your own server, you can separate out different types of content as well (in WordPress this is called “post formats”). You can also post something privately, only giving access to authenticated users.
Adding a friend and subscribing to multiple platforms on which they publish
The key is to connect the different types appropriately. By fetching the content from your friends and placing them in such “buckets,” you now have the option to view everyone’s content from multiple perspectives: everything from a single friend (or a group) across content types, or everything across friends of just one content type.
By continuing to use specialized apps for different types of content, you keep the benefits but exclude the third-party having full access to the content since they now talk to your own server.
Platforms
The possibility to publish on the Internet by using your own server (most of the time: rented web space) is well-established since blogging was invented. It can become clunky when you interact with others: how do I respond?
That’s why there are several reasons why platforms are appealing:
It’s easy to connect with others on the same platform.
Leveraging network effects is easier since the platform knows who is connected to whom.
Spam is usually under control.
Thinking back to the era of blogging, we had lots of interactions with others using comments and pingbacks. What mainly led to its demise was automated spam which reduced everybody’s willingness to be open for interaction. Commenting meant moderating spam.
Core
So one of the core features of the Friends plugin is to solve the authentication problem between people you know and trust.
When you decide “to become friends” with someone, it means that you both get (low privilege) accounts on each other’s servers.
You can give them permission to see your privately published content, or not. When you want to respond to their post, you are automatically authenticated on their side.
This means that you could close comments for unauthenticated users (thus eliminating spam) but keep the discussion open for your friends.
Transitioning
Using your own server still has a learning curve. Getting started with a self-hosted WordPress and installing the Friends plugin is not as trivial as creating an account on a social network.
While it has become considerably easier to register a domain, get webspace connected, and a WordPress installed, there are still many further steps until you really can get started.
So, reality is that your friends likely won’t be migrating off third-party networks. Possibly never.
To still allow yourself to disconnect, the Friends plugin allows you to follow your friends across different (possibly third-party) channels including popular social networks like Twitter.
You can subscribe to someone on Twitter and their messages will be aggregated on your server under their user, in the respective post format.
This means that you can either view all the content (that you follow) for a single friend, or you can view the aggregate type of content, e.g. all the short messages your friends posted across services.
Not only for “real” Friends
Many use social networks to not only follow people they know and trust, but also to follow the news or celebrities. Despite the name of the Friends plugin, it can also do that.
You can subscribe any supported content (some out of the box, for others you can extend it with plugins) but not go into the friendship realm.
Your server takes care of fetching the content from various third-party sources and you can then consume the content in the way you see fit:
The local “Friends UI” on your own server,
an RSS reader,
or more specialized clients like mobile apps.
Ads
One side-effect of this could possibly be that this removes our content from being wrapped in ads and websites trying to have us spend as much time as possible on their site.
We’d all spend a little money for domain and server every month or year for our own gain. We don’t need to put ads to our content.
For journalistic content it is already not uncommon for tech publications to provide an ad-free RSS feed as part of their paid subscription.
More Ideas
You can use your server to store more things, for example:
Your personal bookmark collection and todo lists (I have a work-in-progress for transitioning my previous project called thinkery.me to a WordPress plugin thinkery to host this yourself and use the Android app as a client).
Right now, this is only implemented for WordPress, and the authentication is only leveraged for consuming private content and posting comments. But it doesn’t need to end there.
The authentication could be used for further actions, for example you could give posting permissions to your friends to create a (private) forum, hosted by you or a friend.
The Friendship protocol is a REST API that can be implemented in other software as well.
How far along the way is the Friends plugin? It’s already well usuable for your own purposes. Like I said above, you can establish friendships between servers and consume your friends’ content, even from third-party social networks.
There is still a lot to do, especially around commenting and notifications. Better tools are needed for leveraging network effects, like search your friends+ posts and explore their friends (if they allow you to do so).
I read a lot of web articles on my e-reader (often using Push to Kindle which is fantastic). I left the Kindle ecosystem a while ago and Pocketbook (a TouchHD 3) has been a good home so far.
Since my content is often a mix of text and non-text, I was appealed by a color eInk screen. The Pocketbook Color recently came out and I purchased one to test it.
Here are my conclusions after about two weeks of usage:
Pro
While limited in their range, colors work well for diagrams, illustrations and screenshots. Photos can look a bit awkward but it’s definitely better than greyscale.
Before this e-reader, I haven’t read comics on a device but with color it’s quite fun. The clipping tools in the UI are useful to get rid of white borders around the actual comics.
Con
It’s not very suitable for night time reading (which is my main use case), the minimum brightness is high, there is only white backlight.
With the strong white backlight it feels like an LCD screen which kind of diminishes the idea behind eInk.
The technology seems to use two layers: one “common” 300dpi greyscale, and one around 150dpi color layer. This results in a pattern overlaying the whole screen making the screen less crips when reading text.
Pocketbook readers are rather slow. I always wonder how they do scrolling and inertia so much better than Kindles but feel so. slow. navigating through the UI.
Overall, I think color eInk is technology well worth exploring, especially when no backlight is necessary and it doesn’t need any battery power (think photo walls)
I am torn whether I’ll keep the Pocketbook Color as my main reading device because using the reader in the dark is like turning on the light in the room.